This is the text of a skillshare I delivered at The Sourcery, an awesome commission-less recruiting service. Not only is their model nifty, but they care about actually knowing what they’re recruiting for—so hopefully there isn’t anything too wrong below.
You probably don’t know JavaScript. Like really know javascript.
Javascript is a real programming language: functions, lambdas, closures, objects, inheritance, passing by reference, etc.
Somewhere long, long ago, an arbitrary decision was made that we would “program” a web browser with Javascript. Javascript is good at this (we’ll soon learn why), but there are experimental browsers that use Python (and other languages) to manipulate a web browser window too. There is no inherent reason that Javascript has to be tied to the web browser (or web browsers have to be tied to Javascript).
Unfortunately because the primary context we experience Javascript is in the web browser, we more strongly associate JavaScript with its browser-specific functions/extensions (for manipulating the DOM and listening for UI clicks) than its core language which can exist completely separately from the web browser. Just like we can use Ruby for general purpose programming without using Rails.

If you only think of Javascript in the context of the browser, you’re really missing out; Javascript as a language is badass: lambdas, closures, inheritance, passing by reference.
Why did JavaScript come to dominate the web browser? JavaScript is really good in a browser because as a language it easily supports event-based and asynchronous programming.
-
Event-based: when programming a web browser, most of the actions you want to wire up are “when the user clicks on this, perform a different action than when they click on that.” You declare what event(s) you want to listen for and the resulting action/function you want to take place / be called when you “hear” that event take place.
-
Asynchronous: when you’re interacting with a web page, you’re downloading new data (or images or video) that might take a second or two (or more for video!) to arrive over the wire. You don’t want to just freeze the browser while you wait for it to load, instead you want it to load in the background, then kick off some action when its complete (“completed loading” is another example of an event).
(Remember, we’re talking about these properties as being inherent to the Javascript language itself, not just the functions/extensions that help it interact with the web browser while its doing these things).
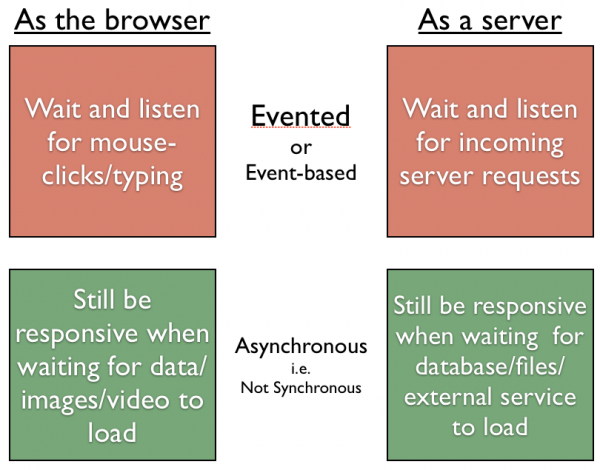
Turns out that the same properties that make javascript work well for interacting with a web page are also very similar to what’s needed for building a good web server.
-
Event-based: a server will constantly be getting requests (at different urls, on different ports) that need to be responded to in different ways when those events take place
-
Asynchronous: in dealing with a request, a server will need to load other data (from a file, a database, another server like Twitter), and you don’t want your entire server to just lock up while it waits for that external service (we call this I/O for “Input/Output”) to finish. For a typical web request, the majority of time will be spent waiting on I/O.
So how are other languages that aren’t (for the most part) event-based/asynchronous used on web servers? Like Ruby, Python and PHP. The synchronous code runs on top of an asynchronous web server (Apache, Rack, WSGI) that creates a synchronous “thread” to run your Ruby/Python/PHP code. If another request comes in while that first thread is still processing, the web server creates a new thread. Unfortunately, those threads are resource-intensive which means you can only create a limited number of them (based on how powerful your server is). If all your threads are in-use, a new request will have to wait until a previous request is finished and the thread becomes available again.
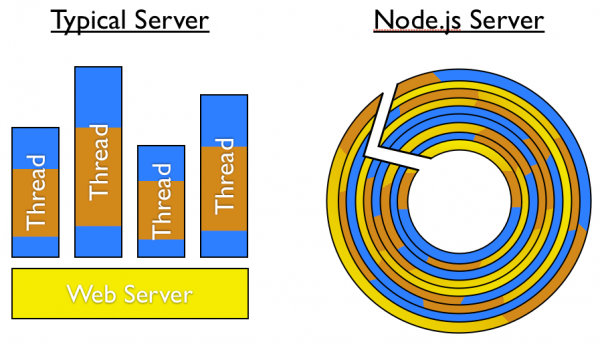
So what happens when you build the entire web server in Javascript: You get Node.js! Instead of adding web-browser functions/extensions to the Core Javascript language, Node.js adds server functions/extensions e.g. managing http requests, filesystem operations, talking to databases, etc. While Node.js runs everything on one single “thread”, because Javascript is event-based/asynchronous we can serve hundreds (if not thousands) of simultaneous requests at once because Node.js doesn’t have to freeze/lock for the “I/O” (“In/Out” e.g. database, filesystem, external-service) processes to finish… Node.js can just answer another request (and another) while waiting for first request’s (and subsequent requests’) I/O process to complete, then come back to it and do the next step in responding to the request. Node.js is a master delegator.
So what can you do when you’re able to quickly serve hundreds/thousands of simultaneous connections?
-
Proxy servers / Service “Glue” / Data Plumbing: routing/piping data between different servers, services or processes
-
Telemetry / Analytics: catch and analyze data as events take place in your system
-
Real-time connections to the web-browser: Traditional/Threaded systems try to keep their connections brief (because they can only handle a few at a time). If you don’t have that few-at-a-time constraint, you can leave the connection open much longer and thus easily send data back and forth in real time. Socket.io is a library for doing this.
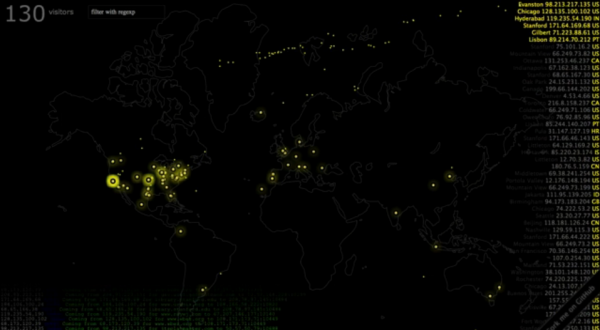
Example of all 3: visualizing traffic going through a Node.js load-balancer by geolocating the requesting IP address and sending them to a map in the web browser in real-time via Socket.io: http://vimeo.com/48470307
Alternatives to Node.js: EventMachine (Ruby) or Twisted (Python). Unfortunately, the majority of Ruby/Python libraries aren’t written to be evented/asynchronous, which means you can’t use those libraries in an asynchronous environment (because they will lock it up). Whereas the majority of Node.js/Javascript code *is* written to be evented/asynchronous.
So if Node.js is so badass, why not use it for everything?
-
CPU Blocking: because Node.js runs on only a single thread, any local processing you do (e.g. NOT database/service calls) locks the thread. For example, processing heavy numerical/algorithmic processing, or generating complicated HTML templates. Node.js works best when you do that data processing somewhere else (for example, in SQL or map/reduce database), and just sending along raw data (like JSON). This is why you’ll often see Node.js powering a thin API (calling out to a database and serving up some JSON) rather than a full-stack MVC implementation (like Rails/Django). This is why Node.js (backend server API) and single-page web apps like Backbone (frontend client-generated UI) are a powerful combination.
-
Javascript as a language can be a pain in the ass: because JavaScript has spent so much time solely in the browser, it hasn’t gotten the love it deserves. It’s tough to fix things because of backwards compatibility (there are so many different browsers that would need to be updated, and web-compatibility is already hard enough). ECMA Script (the official Javascript “standard”) is evolving. Also, there are many javascript cross-compilers that allow you to write your code in another language, then convert it to javascript; example: CoffeeScript, Clojure, Dart.
Still, the opportunities that Node.js creates are worth it. Other fun stuff/opportunities for Node:
-
Sharing code between Server and Browser: Node.js being in Javascript (like the browser) creates the opportunity to share code between your server and client (keeping things DRY), which makes it easier to create persist server-like functionality on the client (for example, if you’re on a mobile phone and your connection drops, you can still use the web-app until it reconnects). Meteor.js is provides a framework for this (and much more, they entirely muddle the distinction between server and client)
-
Pre-rendering browser content on the server: Typically you don’t want to do heavy CPU processing on the Node server, but maybe you’re working with really lightweight clients and you want to “emulate a web-browser” on your more powerful server. Example: Famo.us pre-renders DOM translations in their tech-demo so it will run on devices like the Apple TV
Follow-up Questions:
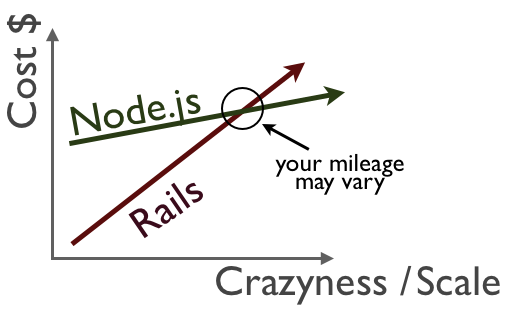
So if Node.js + Backbone is a “powerful combination”, why don’t we just ditch Rails entirely?
The Rails ecosystem is more mature than Node’s: there are more engineers, more libraries, stronger conventions and a more complete development and deployment pipeline (scaffolding, testing, continuous integration, monitoring, etc.). If you have a startup with a limited development window and a typical product design (“users create accounts, post content, favorite other user’s content, see what was most favorited content”) that you need to quickly/agilely iterate, Rails has that problem solved (this is the strength of Rails over pretty much everything, not a weakness of Node specifically). If you’re looking at a cost curve, the starting cost for Rails will be way lower for a vanilla product. Now if you’re talking about doing something non-typical (realtime interaction) or are operating at a huge scale (where you can swap infrastructure costs for engineering costs), Node is enabling (there are some things you just can’t/don’t want to do without Node) if not affordable. Also, you can use Node in a heterogenous environment (running the load balancer, or analytics server) or integrate a Node-powered service into a more traditional product (for example, real-time chat is powered by Node, but user accounts, relationships and chat history is managed by Rails).